前言
具备检测相关经验的同学可能都对yara匹配引擎比较熟悉了,看雪论坛上也有非常详细的翻译文章 - 编写Yara规则检测恶意软件
本文主要对yara文档容易被忽略的部分进行了翻译和总结,并且给出一些进阶用法的例子,提高对yara匹配引擎语法的理解程度。
参考文档:**
https://yara.readthedocs.io/en/v4.2.3/writingrules.html
匹配字符串
yara的匹配字符串可以使用一些修饰符,总结下来有如下部分:
| 关键词 | 支持的字符串类型 | 概括 | 限制 |
|---|---|---|---|
| nocase | 文本,正则表达式 | 忽略大小写 | 不能与xor、base64、 或base64wide一起使用 |
| wide | 文本,正则表达式 | 通过交错空 (0x00) 字符来模拟 UTF16 | 无 |
| ascii | 文本,正则表达式 | 匹配 ASCII 字符,仅在wide使用时才需要 | 无 |
| xor | 文本 | 匹配具有单字节键的 XOR 文本字符串 | 不能与nocase、base64、 或base64wide一起使用 |
| base64 | 文本 | base64 编码的字符串(分割成3条) | 不能与nocase、xor、 或fullword一起使用 |
| base64wide | 文本 | base64 编码的字符串(分割成3条),然后交错空字符,如 wide | 不能与nocase、xor、 或fullword一起使用 |
| fullword | 文本,正则表达式 | 匹配前后没有字母数字挨着的字符(串) | 不能与base64或一起使用base64wide一起使用 |
| private | 十六进制、文本、正则表达式 | 匹配不包含在输出中 | 无 |
base64修饰符
1 | rule Base64Example1 |
将至少会匹配如下三个字符串:
1 | VGhpcyBwcm9ncmFtIGNhbm5vd |
看起来很奇怪,原因如下:
base64是将三个字节变成四个字节,如果不能被整除,那就会涉及到补位,同样的字符串可能因为前缀的不一样导致编码结果不同,这个不一致的循环次数是3,看如下的编码结果就明白了。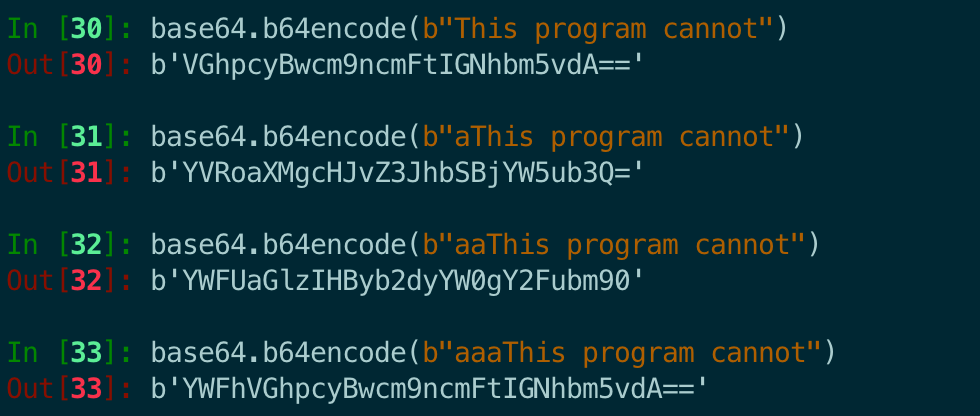
三个结果对应这三个不同前缀。
详情请阅读文档:https://www.leeholmes.com/searching-for-content-in-base-64-strings/
另外base64和base64wide修饰符支持自定义的字符码表,可以匹配一些被修改过的base64编码。
1 | rule Base64Example2 |
XOR修饰符
xor 修饰符是将声明的字符串按照 [0x01 - 0xFF] 都进行单字节异或,例如:
1 | rule XorExample1 |
等价于:
1 | rule XorExample2 |
另外还支持参数,限定xor的范围:
1 | rule XorExample5 |
匹配条件的语法
支持的运算符
所有运算符的优先级如下:
| 优先级 | 操作 | 描述 | 性质 |
|---|---|---|---|
| 1 | [] . |
Array subscripting 数组下标 Structure member access 结构成员访问 |
从左到右 |
| 2 | – ~ |
Unary minus 按位减 Bitwise not 按位非 |
从右到左 |
| 3 | *** \ %** |
Multiplication 乘法 Division 除法 Remainder 取余 |
从左到右 |
| 4 | + – |
Addition 加法 Subtraction 减法 |
从左到右 |
| 5 | << >> |
Bitwise left shift 按位左移 Bitwise right shift 按位右移 |
从左到右 |
| 6 | & | Bitwise AND 按位与 | 从左到右 |
| 7 | ^ | Bitwise XOR 按位异或 | 从左到右 |
| 8 | | | Bitwise OR 按位或 | 从左到右 |
| 9 | < <= > >= |
Less than 小于 Less than or equal to 小于等于 Greater than 大于 Greater than or equal to 大于等于 |
从左到右 |
| 10 | == != contains icontains startswith istartswith endswith iendswith matches |
Equal to 等于 Not equal to 不等于 String contains substring 包含 Like contains but case-insensitive 包含不区分大小写 String starts with substring 以开始字符串 Like startswith but case-insensitive 以开始字符串不区分大小写 String ends with substring 以结尾字符串 Like endswith but case-insensitive 以结尾字符串区分大小写 String matches regular expression 正则表达式 |
从左到右 |
| 11 | not | Logical NOT 逻辑非 | 从右到左 |
| 12 | and | Logical AND 逻辑与 | 从左到右 |
| 13 | or | Logical OR 逻辑或 | 从左到右 |
字符串计数
1 | rule CountExample |
还能指定范围计数:
1 | #a in (filesize-500..filesize) == 2 |
字符串偏移或者虚拟地址
1 | rule AtExample |
取字符串第i次出现的偏移,注意只能用 == 运算符
1 | rule AtExample |
匹配长度
这个主要用于正则表达式,比如 /fo*/可以匹配字符串 ‘fo’, ‘foo’,’fooo’等,但是具体要选择哪一个呢?这里可以用!来去匹配长度:
1 | rule MatchLength{ |
访问指定位置的数据
使用以下函数从给定偏移量的文件中读取数据:
1 | int8(<offset or virtual address>) |
1 | rule IsPE |
字符串集合
1 | 2 of ($a,$b,$c) |
for循环
对多个字符串使用相同的条件
1 | for expression of string_set : ( boolean_expression ) |
其实这里可以发现any of 是一种简写:
1 | any of ($a,$b,$c) |
在 expression 中也可以使用 @, # ,! 等运算符:
1 | for all of them : ( # > 3 ) |
迭代字符串
可以使用以下语法访问给定字符串出现在文件或进程地址空间中的偏移量或虚拟地址:@a[i],其中 i 是一个索引,指示出现了你所指的字符串 $a 。(@a[1]、@a[2]、…)
1 | rule Occurrences |
以上条件也可以写成:
1 | for all i in (1..3) : ( @a[i] + 10 == @b[i] |
另一个规则:
1 | for all i in (1..#a) : ( @a[i] < 100 ) //#a 代表 $a 出现的次数 |
还有可以限定满足条件的迭代次数:
1 | for 2 i in (1..#a) : ( @a[i] < 100 ) |
迭代器
在 YARA 4.0 中,for..of运算符得到了改进,现在它不仅可以用于迭代整数枚举和范围(例如:1,2,3,4 和 1..4),还可以用于任何类型的可迭代数据类型,例如YARA 模块定义的数组和字典。例如,以下表达式在 YARA 4.0 中有效:
1 | for any section in pe.sections : ( section.name == ".text") |
在迭代字典时,您必须提供两个变量名,它们将保存字典中每个条目的键和值,例如:
1 | for any k,v in some_dict : ( k == "foo" and v == "bar" ) |
外部变量
外部变量允许您定义依赖于外部提供的值的规则。
1 | rule ExternalVariableExample1 |
在这种情况下ext_var是一个外部变量,其值在运行时分配。外部变量可以是以下类型:整数、字符串或布尔值;它们的类型取决于分配给它们的值。整数变量可以替代条件中的任何整数常量,布尔变量可以占据布尔表达式的位置。例如:
1 | rule ExternalVariableExample2 |
string类型的外部变量可以与以下运算符一起使用:contains、startswith、endswith及其不区分大小写的对应运算符:icontains、istartswith和iendswith`。它们还可以与“matches运算符一起使用,如果字符串与给定的正则表达式匹配,则返回true。
1 | rule ContainsExample |
偏门模块
- Hash模块
https://yara.readthedocs.io/en/latest/modules/hash.html
- Math模块
https://yara.readthedocs.io/en/latest/modules/math.html
- Dotnet 模块
https://yara.readthedocs.io/en/latest/modules/dotnet.html
一些进阶用法
打分
利用yara的math模块进行打分
1 | math.to_number(SubRule1) * 60 + math.to_number(SubRule2) * 20 + math.to_number(SubRule3) * 70 > 80 |
判断.text section的墒值在7.4与7.6之间
1 | for any section in pe.sections : ( |
导入表有且仅有VirtualAlloc 和 CreateRemoteThread 以及 _WriteProcessMemory_
1 | pe.imports("kernel32.dll","VirtualAlloc") |
有某个图标,并且无签名(不够灵活,没法设定一个hash列表)
1 | import "hash" |
匹配PDB路径
1 | pe.pdb_path icontains "shellcode" or pe.pdb icontains "qianxin" |
匹配特征在具体的节区
1 | import "pe" |